As with many software engineers / AI engineers these days, I mostly interact with only language models to prototype or develop software. While they still need supervision, I am amazed at how far language modelling has advanced in just the last 5 years. It was not too long ago that we were modelling simple text prediction using classic models such as Hidden Markov Models (HMMs) or early recurrent neural networks such as LSTMs / GRUs. So what happened?
In my view, two major improvements in architecture and optimisation.
After the revival of deep learning with AlexNet, recurrent neural networks (RNNs) capable of predicting the next token were a natural evolution of classic models such as HMMs. Even until 2020, bi-directional RNNs with Attention were performing at SOTA level for text modelling. But for all that RNNs could achieve, it had a critical weakness – text had to be sequentially given to the model. To solve this critical limitation came Transformers, which became the foundation of today’s large language models. Transformers, in their essence, had only two key improvements – positional encoding of input text and layers of self-attention units – paving the way for the relaxation of the sequential input constraint in previous RNN models and improved parallelisability, leading to the ability to leverage web-scale volumes of text data. This again goes to show that general methods that leverage computation are ultimately the most effective.
The biggest lesson that can be read from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin. The ultimate reason for this is Moore’s law, or rather its generalization of continued exponentially falling cost per unit of computation.
– Rich Sutton
But the most fascinating discovery, which is not discussed as much as it deserves, is the double descent phenomenon in the over-parameterized or modern regime of parameter size, as we call it now. Any student who has taken a classic machine learning class before 2020 should be familiar with the classic bias-variance curve of training models: when you keep training a model on the training set both training error and the test error keeps dropping until some point after which the test error starts increasing while the training error keeps dropping. This point is the point where the model starts overfitting to the training signal. This behaviour was so fundamental and logical in machine learning that no one doubted it. But to the astonishment of everyone (at least to me, I remember the first time I saw the paper) large parameter models displayed dual descending behaviour. They overfit, but when you keep training, the test error again keeps decreasing and it keeps going: larger the model, better the generalisation. Additionally, there were emerging skills, also known as grokking, rumoured to have been discovered accidentally, when a researcher left their model training overnight. So how do we explain this magic?
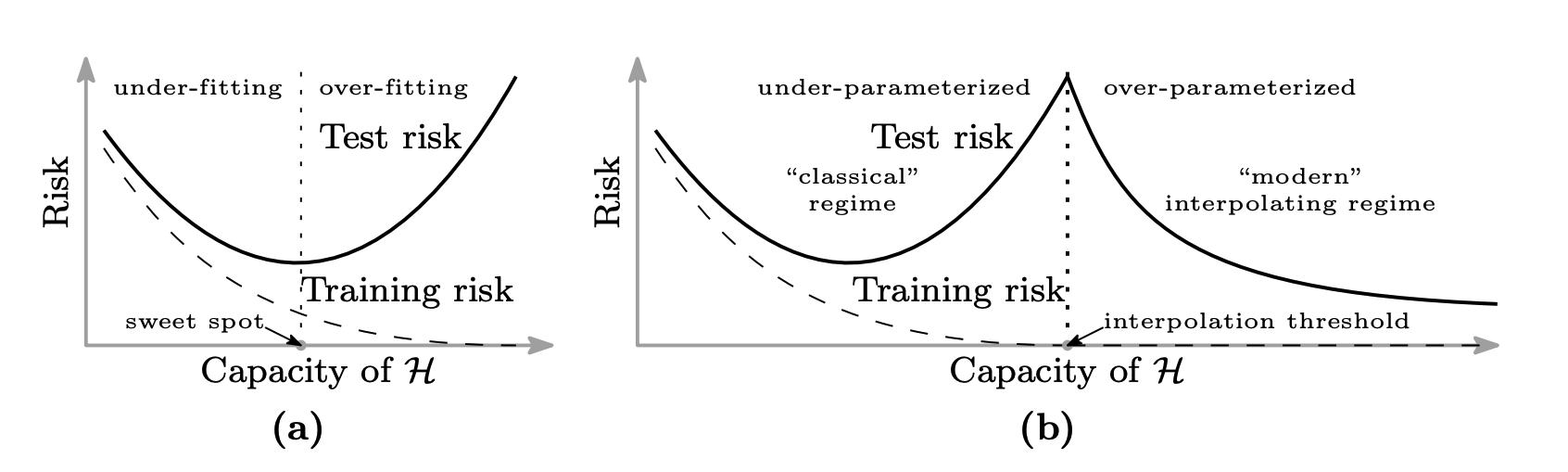
With classic ML models, after some point in the optimization curve, the model starts capturing spurious signals in the training data set, which makes it overfit to the training set. The current prevailing theory with large models with billions of parameters (i.e. over-parameterized regime) is that they have enough capacity to memorise spurious signals (or functions) and still have capacity left to generalise through an infinite number of functions. The larger the model and dataset, the better the generalised signal. This is also why it is not simply next token prediction that has enabled modern LLMs to achieve such human-like (or even superhuman) generalisation ability. Next token prediction is only the tip of the iceberg; the actual magic happens on the optimisation side.
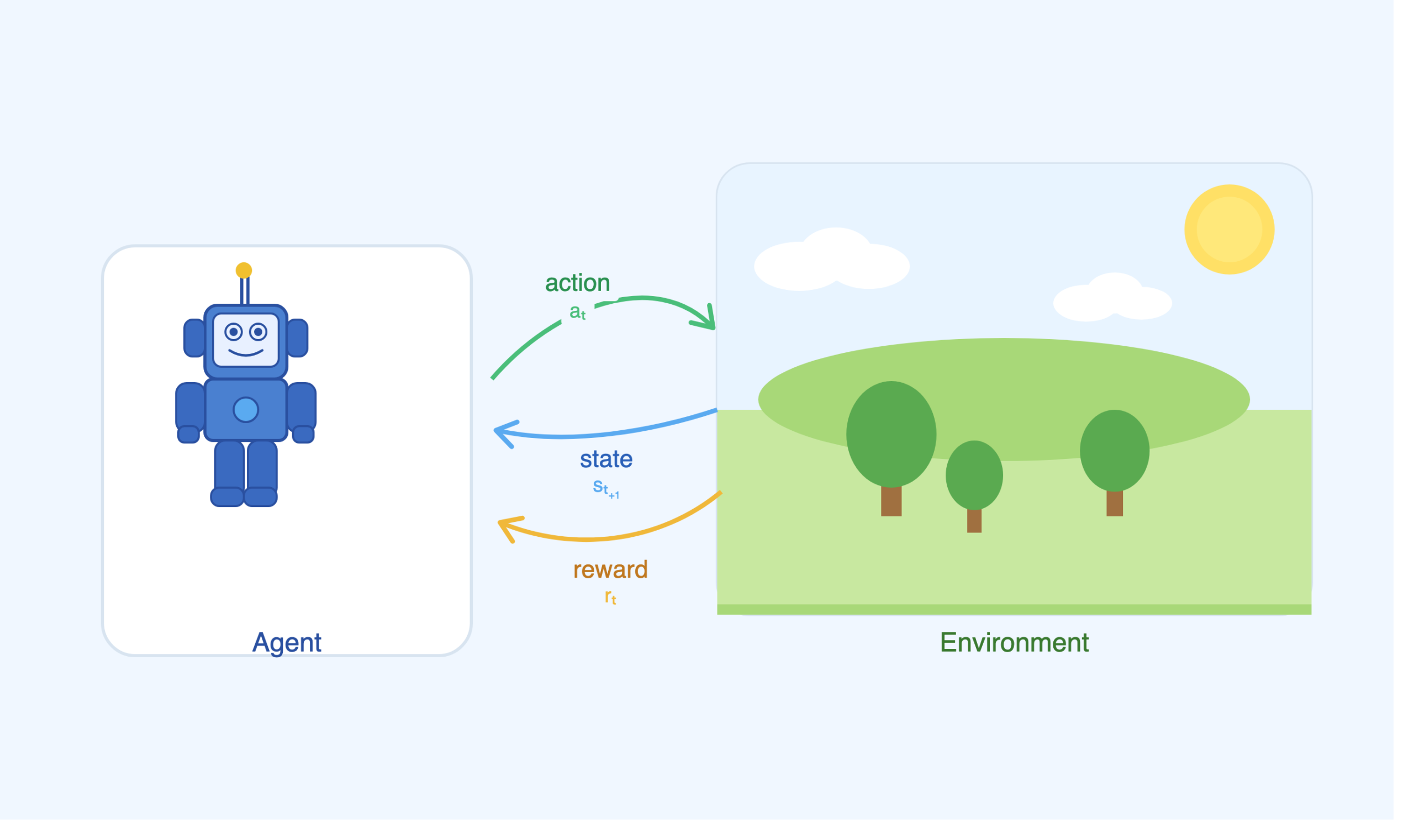
And what role has reinforcement learning (RL) played in this optimization process? In its essence, RL optimises for the expected discounted cumulative return. In layman’s terms, this means given a multi-step task with hundreds of moves/actions, you can optimize the sequence of actions such that they lead to the final positive outcome with high probability. This fits well for long sequences of text generation, where each word is an action that comes before the end of the sentence and the reward comes from how well that full sentence aligns with the desired or human-like answer.
But going beyond such functional aspects of RL fitness, are there more abstract reasons why RL would elicit advanced skills in models? Indeed, researchers argue that RL-like learning (reward-based, trial and error) could bring forward advanced skills that we see in animals. But practically RL generally has a major Achilles’ heel: we usually need millions of trial and error signals for an agent to learn a good policy (i.e. a state–action mapping). However, if you can learn a good representation for a task, arguably, reward could indeed be good enough for any difficult task and even elicit emerging skills. With the level of advanced skills LLMs demonstrate at the moment, next token prediction with Transformer architecture seems to have elicited such a latent representation that is compatible with RL training to finish the last mile, so as to speak.
In the end, since everything usually leads back to money, the behaviour of models in the over-parameterized regime has translated into unhinged capitalism: the more capital you have, the better results you get. And as we have seen in the last few years, this double descent phenomenon has led to a modern black-gold race in the form of a chip race for higher-end GPUs and training bigger and bigger models. As far as I know, we have still not seen the end of returns as parameter size increases, though scaling has begun to show diminishing returns, improved model architectures and more data continue to push the boundary. Notwithstanding these improvements, current model capabilities have already ushered in a new technological revolution, with a plethora of economical, political, psychological, security and overall social challenges left in its wake. And the fact that this revolution happened so swiftly has left the world still trying to grasp the consequences, much less finding solutions.